Streamlining Data Extraction with AWS Textract and Python: A Comprehensive Guide for Developers


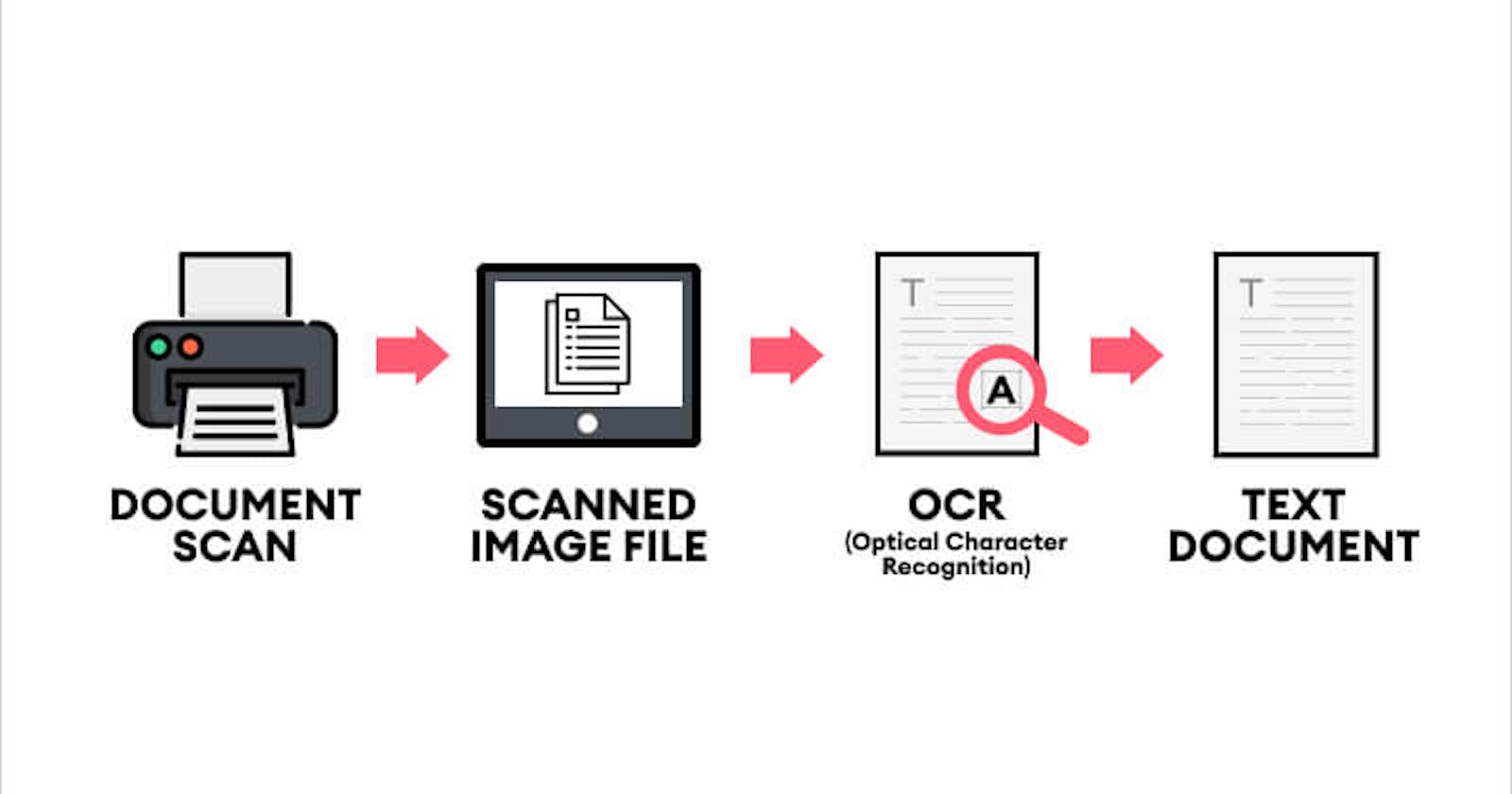
AWS Textract, a powerful cloud-based Optical Character Recognition (OCR) service provided by Amazon Web Services, enables developers to extract structured data from scanned or printed documents with ease. Developers may automate and expedite data extraction procedures by utilising AWS Textract's features as well as the Python programming language's simplicity and flexibility. The strong combination of AWS Textract and Python will be explored in depth in this article, along with a step-by-step tutorial and example code for data extraction from documents.
Prerequisites
Make sure you have the following conditions in place before beginning the integration process:
An AWS account: Ensure that you have an active AWS account to access AWS services, including Textract.
Python and Boto3: Install Python on your system and set up the Boto3 library, the AWS SDK for Python, which allows interaction with various AWS services.
Integration Steps
Step 1: Set up AWS Textract
To begin, you need to enable AWS Textract in your AWS account. Open the AWS Management Console, navigate to the Textract service, and follow the instructions to enable it. Note down your AWS access key and secret access key, as you will need them for authentication in the Python code.
Step 2: Install Boto3
Install Boto3, the Python library for AWS services, by running the following command in your command prompt or terminal:
pip install boto3
Step 3: Configure AWS Credentials
Configure your AWS credentials by creating a credentials file or using environment variables. This step ensures that your Python code can authenticate and access the AWS services. For example, you can create a credentials file at ~/.aws/credentials with the following format:
[default]
aws_access_key_id = YOUR_ACCESS_KEY
aws_secret_access_key = YOUR_SECRET_KEY
Step 4: Write Python Code for Data Extraction
Now, let's write Python code to extract data from a document using AWS Textract. Below is a sample code snippet to get you started:
import boto3
def extract_text_from_document(bucket_name, document_name):
# Create a Textract client
textract_client = boto3.client('textract')
# Specify the S3 bucket and document name
s3_object = {'Bucket': bucket_name, 'Name': document_name}
# Start the Textract job
response = textract_client.start_document_text_detection(
DocumentLocation=s3_object)
# Get the job ID
job_id = response['JobId']
# Wait for the job to complete
textract_client.get_waiter('document_text_detection_completed').wait(
JobId=job_id)
# Get the results of the completed job
result = textract_client.get_document_text_detection(JobId=job_id)
# Extract and return the text
extracted_text = ''
for item in result['Blocks']:
if item['BlockType'] == 'LINE':
extracted_text += item['Text'] + '\n'
return extracted_text
# Call the function with your desired S3 bucket and document name
bucket_name = 'your_bucket_name'
document_name = 'your_document.pdf'
extracted_data = extract_text_from_document(bucket_name, document_name)
# Print the extracted data
print(extracted_data)
Step 5: Run the Python Code
Save the Python code to a file, such as textract_extraction.py, and run it in your Python environment. Make sure to replace 'your_bucket_name' and 'your_document.pdf' with your actual S3 bucket name and document name.
Conclusion
By integrating AWS Textract with Python, developers can harness the power of OCR to automate data extraction from scanned or printed documents. This article provided a step-by-step guide to integrating AWS Textract with Python, enabling you to extract structured data from documents effortlessly. With the sample code provided, you can get started on your journey to streamline data extraction processes and unlock valuable insights hidden within your documents.